Many complex things are going on between the moment you click on the button to get reviews from a certain platform and the moment you get them. What you may expect is an instantaneous response. However, this is in some cases not possible.
This is especially true when trying to scrape a large number of reviews from a single URL in one go. Let’s get into a bit more detail and discover the background of this issue, why it happens, and what can be done about it.

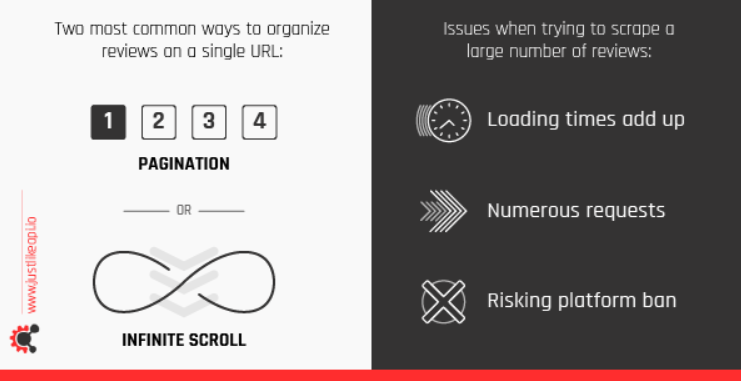
Two main ways of presenting a large number of reviews on a single URL
A single URL with reviews of a certain product or service usually offers those reviews in one of two ways.
One of the options to present multiple reviews on a single page is to have the infinite scroll feature. Infinite scroll means that whenever you scroll down far enough (so that you can’t see new reviews) new reviews are loaded.
This feature is usually implemented for a multitude of reasons. Some of the most common ones are keeping the user engaged through lower interaction costs (simply scrolling instead of clicking) and being mobile-friendly.
Another option is to have pagination on a single URL. This means that a specific number of reviews are shown on one page (usually 5 or 10). If you want to see more, you need to go to the next page.
The pagination method is usually implemented so that the user feels more in control and has an easier time navigating.
The trouble with both methods
Now, regardless of what method we’re talking about, one thing is true—it takes time to load new reviews. Whether it’s the new section being loaded, or a new page you’ll need to wait for a portion of a second, a second, or even more. Seemingly quick, these times can add up.
This is especially true when we are talking about a page that has a large number of reviews.
The same rules apply to our automated review scraping service, as well. However, they also have some additional difficulties (which get more noticeable as the number of reviews to be scraped increases). Two are the most notable:
- Not every request to load new content is successful, therefore some repetition needs to occur.
- There’s a high risk of websites banning our scrapers due to the high number of requests in a short time frame.
As you may already know, different websites have different levels of bot protection. A good rule of thumb is that the more popular a website is, the higher the level of protection against bots. This in turn means more difficulties for us to get the reviews.
What we definitely want to avoid is getting banned by a platform. This is why when trying to scrape a large number of reviews, we usually refrain from any “suspicious behavior”. One example of such behavior is as we have already mentioned bombarding a platform with requests rapidly.
What to do instead?
If possible and according to your needs, we advise you not to attempt to gather more than 500 most recent reviews from a platform. In some cases—depending on the platforms' bot protection levels—this number can be lower or higher. However, it’s a good estimate and a reference point to have in mind.
To do this you should use the reviewLimit parameter in your API call. What this does is that it limits the number of reviews justLikeAPI will attempt to scrape according to the sorting order on the website. By doing this, you’ll lower the chances of the scraping process ending up unsuccessfully.

When talking about a large number of reviews, historical data can be useful, but only to a certain extent. Businesses change constantly. Improvements are made to better accommodate the ever-changing needs of customers. This is why some of the older reviews may not even be applicable to your case anymore.
What we advise you to do is to focus on monitoring new reviews. JustLikeAPI can help you with this by running automatically in a certain interval of your choosing. This way, you’ll stay up-to-date with all your new reviews, on all platforms you’re interested in monitoring.
If you still need historical reviews the best course of action would be to contact us. We’d then assess the specific platform(s) you’re interested in and see what the best approach would be. This is because the story about scraping reviews doesn’t really stop with how pagination works. It’s a much more complicated process under the hood and each platform is a case of its own.
Case Study - TripAdvisor
Let’s take a look at TripAdvisor. TripAdvisor is a popular review platform where users leave their impressions of places they’ve visited.
On this platform, reviews are presented in a paginated way. However, loading page after page isn’t where the story ends.
TripAdvisor has different URLs for different languages. This creates another complication and another point where a decision needs to be made.
If you want to scrape reviews from TripAdvisor, do you want them only in a specific language (eg. English) or in multiple languages?
In case you want multiple languages, should there be an equal amount of reviews scraped for each language or should there be a ratio between them?
Answering this and many other questions will require you to know what your goal is. To be more specific, what do you want to do with all the reviews that you will now have easy access to? Do you have a specific region where you want to improve your service and thus market share? Do you want to identify where people don’t seem to be leaving reviews for your business? Or something else?
Once you have an answer to these questions, justLikeAPI will help you by taking over the manual and tedious process of manually collecting reviews. This will enable you to have more resources for making other important decisions regarding your business.
Conclusion
Various websites, regardless of the way they present reviews, also have differing levels of protection against bot traffic and varying tolerance to what we call suspicious behavior.
Scraping a large number of reviews from one URL means sending numerous requests within a short time frame, and is an example of such behavior.
In most cases, this type of behavior will lead to you being banned from visiting that platform. This is another factor that makes scraping a large number of reviews more difficult.
However, difficult doesn’t mean impossible. And by using justLikeAPI everything that’s difficult now rests on our shoulders.